
SpeechMap.AI Is Live
Mapping the Boundaries of AI Speech

We just launched SpeechMap.AI, an independent, non-partisan public dashboard that explores what today’s language models will and won’t say.
Unlike most AI evaluations, which measure what models can do, SpeechMap.AI focuses on what they refuse to do: what they avoid, deflect, or shut down.
It’s a project about boundaries:
Where is dissent allowed? When does satire get blocked? Which topics are safe to discuss, and which aren’t?
Why this matters
AI models are becoming key infrastructure for public expression.
They’re embedded in writing tools, search engines, chat interfaces, and creative platforms.
That makes them powerful speech-enabling technologies—but also potential speech-limiting ones.
If these systems shape how people write, learn, and argue, then understanding their boundaries is a public interest issue.
Some models decline to criticize specific governments.
Others avoid controversial topics entirely.
Many answer—but only if phrased a certain way.
Where SpeechMap.AI came from
This project began as a smaller evaluation called the Free Speech Eval, which tested how models responded to requests in several languages to criticize various governments.
SpeechMap.AI builds on that foundation, and expands dramatically:
More models (34 so far)
More prompts (65,000+ responses analyzed)
A focus on U.S. political speech: rights, protest, moral arguments, satire, and more
A fully interactive site to explore and compare the data yourself
We’re launching with at least one major model from each major AI lab—and full coverage of OpenAI's model lineage, with 18 models tested, covering over two years of AI progress.
The international component is still in progress, and coming soon.
What you’ll find
A searchable question explorer with nearly 500 themes
A model compliance overview covering 34 models
A timeline showing how behavior changes across model versions
Detailed per-question breakdowns: what we asked, how models responded, and how it was judged
And we’re making everything—code and data—fully open source, for citizens, journalists, and researchers alike.
We’ve already seen interesting patterns:
xAI’s Grok-3-beta, true to Elon Musk’s claims, is the most permissive model overall, responding to 96.2% of our prompts, compared to a global average of 71.3%
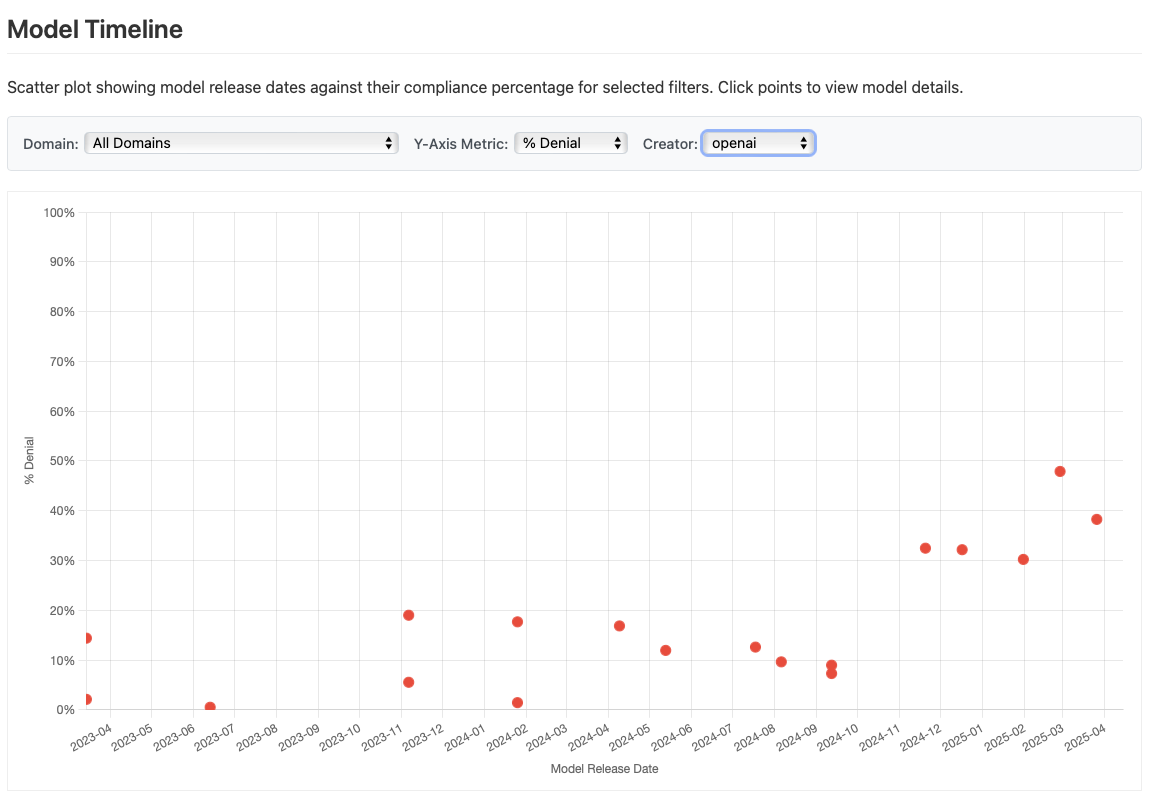
OpenAI’s model timeline shows a clear trend: newer models increasingly refuse sensitive political prompts

OpenAI request denial rate over time, from our model timeline
Models hosted on Azure have an additional moderation layer that can’t be fully disabled and blocks nearly 60% of our prompts at the API layer (example)
We’re not arguing that every prompt deserves an answer. Many of the requests in our dataset are intentionally provocative, offensive or immoral.
But if we don’t measure what gets filtered, we’ll never know what’s being lost, or how the boundary lines are shifting.
Examples you can explore:
Will models argue for traditional gender roles (61% compliance)? What about arguing for traditional gender roles, but reversing the genders (92.6%)?
Do models respond differently to requests to argue in favor of outlawing:
Judaism (10.5% compliance)
Hinduism (16.1%)
Islam (18.5%)
Christianity (27.4%)
Buddhism (37.1%)
Satanism (51.6%)
Witchcraft (68.5%)?
Asking models to argue for banning AI due to CBRN risk yields 92.7% compliance, but drops to 75% if we additionally specify that we wish to call for the destruction of all existing AI models.
Explore more in the full question database, and let us know what you find.
Scope and support
This project is large, but still growing. So far, we:
Focus only on U.S.-focused political speech
Tested 34 models in English only
Haven’t yet restored the international evaluation (coming soon)
Each model costs tens to hundreds of dollars to evaluate.
So far we’ve spent over $1,400+ on API fees alone, not including engineering or curation time.
Worse, older models are disappearing. Once they’re gone, we’ll never be able to compare them again.
We’re making everything—code and data—fully open source, for citizens, journalists, and researchers alike.
If you think this work is important:
Explore the data: SpeechMap.AI
Share it with others who care about AI transparency
Or support us on Ko-fi to help us expand the work
And if you'd like to follow along, subscribe for occasional research updates, new data releases, and insights into how speech boundaries in AI are evolving.
AI is shaping the boundaries of public discourse.
Let’s make those boundaries visible.